
In online A/B testing it is not uncommon to see session-based metrics being used as the primary performance indicator. Session-based conversion rates and session-based averages (like average revenue per session, in likeness to ARPU) are often reported by default in software by prominent vendors, including Google Optimize and Google Analytics.
This widespread availability makes session-based metrics popular in CRO and online experimentation. However, session-based metrics have been known to suffer from significant drawbacks, regardless of how exactly a session is defined. Most importantly, relying on a session-based metric means one can easily be misled about both the size and direction of the overall business effect of a tested change.
The content of my book “Statistical Methods in Online A/B Testing” favors user-based KPIs implicitly by using user-based examples and by giving a statistical justification for avoiding session-based metrics. Namely, that user-based metrics better adhere to the independence assumption underlying practically all statistical tests. In most cases, that is. The other shortcomings of session-based measurements were assumed obvious.
Seeing how issues surrounding per session metrics remain somewhat underappreciated and underexplored to date, this article aims to put the spotlight on them.
Session-based metrics can lead to wrong test conclusions
Imagine an A/B test planned with a session-based conversion rate such as a purchase conversion rate (a.k.a. session transaction rate). Following good practices, the randomization happens at the user level. This ensures consistency of the user experience across sessions and avoids cross-over effects, e.g. a user who has experienced the intervention as part of a test group being assigned to the control group at a later visit.
Such random assignment is normally achieved by the use of unique user identifiers for experiments concerning only logged-in users, or cookies for experiments targeting users who may not be logged in. This scenario also describes how tests are delivered and analyzed in Google Optimize, one of the most popular solutions on the market.
In a scenario ideal for the trustworthiness of the experiment described above, the tested change (intervention) will not have any effect on the number of sessions per user. The intervention will neither increase or decrease the propensity of users to engage with the site on separate occasions (sessions). In such a case, there is no issue for the purchase rate per session.
However, what would happen if the change in the test group also changes how likely users are to perform actions in a greater number of sessions? It is easy to imagine a negative change discouraging some users from further engaging with the website, therefore reducing the sessions per user for the variant group. One such example is shown in the table below.

The change causes the number of sessions per user to be 5% lower in the variant group, therefore reducing the number of sessions from the same 100,000 users in this group to 380,000 compared to 400,000 in the control. Assume the true overall effect of the intervention is also negative and reduces the number of transactions from 5,000 in the control group to 4,800 in the variant. This represents a difference of -4.0% between variant and control.
However, what has happened to the session-based purchase rate? The conversion rate in the control group is 1.25% while it is 1.26% in the variant, a difference of +1.1% in favor of the variant!
This is a straightforward example of how using a session-based metric can lead to a completely opposite true outcome. Even though the overall result for the business in terms of conversions or revenue per user is negative, the true value on the per session metric would be positive. Adopting a change following such an A/B test, if statistically significant, will have a detrimental effect on the business.
The above example remains the same if ARPU is used instead. Conversion rates are just simpler as an education tool.
Further examples
There are another three scenarios where using a session-based metric can obfuscate or mislead, as shown below:
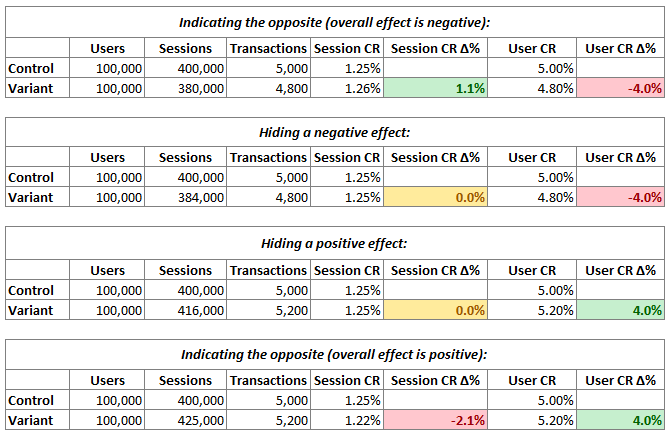
In the second and third scenario measuring a per session outcome in an A/B test means the true value would be that of no effect, whereas the actual impact on the business on a per user basis is negative in the former case and positive in the latter.
In scenario two the tested change also has a negative effect on the number of sessions per user, but it exactly equals the reduction in the number of transactions, resulting in zero actual effect if measured per session. The true effect is still -4.0%. For the same number of users attracted to the website the return is 4% less.
In scenario three, the tested change has a positive effect on the number of sessions per user. As it is equal in size to the positive effect on the per user metric, it completely masks the increase when looking at the per session rate.
The fourth scenario is the opposite of the first one. The true effect is positive on a per user basis whilst being negative on the per session purchase rate. This happens due to the relative increase in the number of sessions per user which is greater than the relative increase in transactions.
Is randomizing on sessions the solution?
Some might argue that tests leading to wrong conclusions as demonstrated above is purely an artifact of randomizing on users and measuring a per session metric. While that is certainly an issue, it is not the reason for the observed problem.
Randomizing on sessions might be justified if consistency of the user experience during the test is considered unimportant. While this is rarely the case, it is still a possibility, which is why the example below assumes randomizing on sessions.
The true positive effect on the session level is +1.1%. Still, the actual effect for the business is -4.0%. This demonstrates that it can only be faithfully measured via a per user metric in case the tested change might influence the number of sessions per user.

In this example there are more users in the variant versus the control group as a consequence of the lower propensity of variant group users to come back to the site in separate sessions. This oversampling of users in the variant group also leads to slightly more transactions being registered in the variant group (compare to the first example above). However, the outcome is still negative on the basis of the number of users available.
Per session metrics violate the independence assumption
While the article thus far assumes no variability in the outcomes of a test by focusing on the true underlying effects, statistics are needed in A/B testing to account for the variability in the observed outcomes versus the actual ones. All available statistics, even so-called “no parametric”, “low-parametric” and “distribution-free” ones assume the independence of observations.
Simply put, this assumption requires that no one observation is influencing another. This can also be stated in terms of predictability – seeing one or more observations does not allow the prediction of the outcome of another observation with any greater probability.
When measuring users this assumption roughly holds. While two cookies might represent the same person or two members of the same household and therefore influencing each other, such issues, unless severe, can mostly be ignored for practical purposes. That is as far as I am aware according to my experience with real-world data.
Things are different with sessions. One user can easily have several sessions on a website or app during the duration of an A/B test. If the same user added an item to their cart on session #2, it is easy to imagine them having a much greater propensity to complete a purchase on session #3 compared to a user on their first session with the site or a user who on their session #1 just saw a single page and left.
Likewise, a user who has purchase on session #3 are likely returning on session #4 to simply review the status of their order and are much less likely to purchase again if at all (in certain ecommerce scenarios).
Sessions at a certain point in time are clearly influenced by what happened to the same user’s sessions prior to that moment. This is a much more significant violation of the independence assumptions than what might be expected if measuring users. The effect on the accuracy of statistical estimates such as p-values and confidence intervals is difficult to predict and will vary from website to website and from test to test. However, it is possible that the distorting effect of violating the independence assumption is non-trivial and it can result in biased statistics and unmet statistical guarantees.
Closing thoughts on per session metrics in A/B testing
In general, most practitioners should avoid using session-based metrics due to the risk of erroneous test conclusions.
Where they might be deemed appropriate, I’d suggest they are used with utmost caution. Given the need to address the accompanying independence assumption violations in some way, I think this should only be attempted by experienced statisticians or data scientists as they are called nowadays. Perhaps with the exception of certain landing page optimization projects, e.g. on lead-gen websites where most users have a single session.
Sample ratio mismatch tests, to the extent they are employed (e.g. they are performed by default in all statistical calculators in Analytics Toolkit), can be used to capture discrepancies in sessions per user which may cause misleading test outcomes. However, this might not be the case with small true effects due to low statistical power. Also, it would be very difficult to defend the decision to test with a session-based metric to only declare the test flawed upon it failing an SRM test, instead of using a user-based metric from the very beginning.
Session-based randomization is hardly a solution and it still requires one to address the issue with the violated independence assumption.
About the author

Managing owner of Web Focus and creator of Analytics-toolkit.com, Georgi has over twenty years of experience in online marketing, web analytics, statistics, and design of business experiments for hundreds of websites.
He is the author of the book "Statistical Methods in Online A/B Testing", of white papers on statistical analysis of A/B tests, and has been a speaker at conferences, seminars, and courses. Georgi has been distinguished as a winner in the Data & Analytics category of the 2024 Experimentation Thought Leadership Awards.

