Some two years after it gained prominence Google Analytics spam is all the rage again with one or several notorious spammers finding their way into hundreds of thousands of Google Analytics accounts in order to bring attention to stuff the spammer or his/her associates are making money off. The new wave started around Nov 8, 2016 with a great amount of language spam traffic that essentially targeted the home reporting screen of Google Analytics where many webmasters saw the phrase
“Secret.ɢoogle.com You are invited! Enter only with this ticket URL. Copy it. Vote for Trump!”
appear in their language report section. Unlike the previous spam waves where the “Source/Medium” and the “Referrals” reports were the main target, this time the attack was in two-dimensions with both the source dimension and the language dimension being spammed.
The delivery mechanism of most of the spam is well-known – it happens via ghost visits that are sent straight to the Google Analytics servers via what’s otherwise a very useful feature – the Measurement Protocol. I won’t go into technicalities here as we’ve done it multiple times before, including with an info-graphic. Instead, let’s take a look at
The Evolution of Google Analytics Spam
Like living things, spam mutates and “improves” through time under various pressures. Unlike previous spam attacks where we would see a single domain/hostname being “promoted” for weeks or even months, this time each domain was pushed to Google Analytics for just about 24h after which it was replaced with a new domain (all .xyz domains).
Here is just of a few of the spam domains and traffic from them over the course of a few days:

We have systems that monitor and detect referrer spam that we then use to operate our Auto Spam Filters anti-GA-spam tool. We would normally pick up on a new source of spam in a day or two and review it to avoid false positives. If it was indeed spam we would add it to our filters and it would be blocked from our client’s Google Analytics views in about 24h (pushing filter inserts & updates to thousands of GA accounts and views takes time, even with an extended quota). Since spam isn’t pushed to all users of GA at once, some of our users would not even begin to see the spam before we deploy our updated filters.
As you can imagine, the above spam behavioral pattern puts us and everybody relying on blacklists (that is, everybody) to block referrer spam in an entirely new playing field. But that is not the whole story of how the spammers improved their way of polluting everyone’s statistics as more was soon to follow.
Initially the new wave of spam had fake, but believable other characteristics such as browser, operating system as well as metrics like bounce rate and average session duration. Soon after the browser field began to be populated with the string “ɢoogle.com”, while the page title dimension had “Secret.ɢoogle.com” in it, adding two more attack vectors. Note that like in “Secret.ɢoogle.com You are invited! Enter only with this ticket URL. Copy it. Vote for Trump!”, google.com is different from ɢoogle.com. The first is a domain operated by Google Inc. (now part of Alphabet) while the second is operated by the spammer.
In short, what was and still is happening is something I warned about way back in early 2015 with my post “All Your Analytics Are Belong to Us” – the spammers are abusing every opportunity they have to grab your precious attention and Google Analytics is caught pants down, no retaliation in sight. This is especially funny in light of some article titles from a few months back which announced “the end of Google Analytics spam“, quite prematurely, as it seems.
Adding insult to injury, the spammer even started promoting the coverage of his activities in the “full referrer” field, pointing webmasters and analysts to pages where his misdeeds were reported on, such as an article on Thenextweb, a thread on Reddit and also to his, believe it or not, own plugin for Firefox. Here is a sample of his “work”:
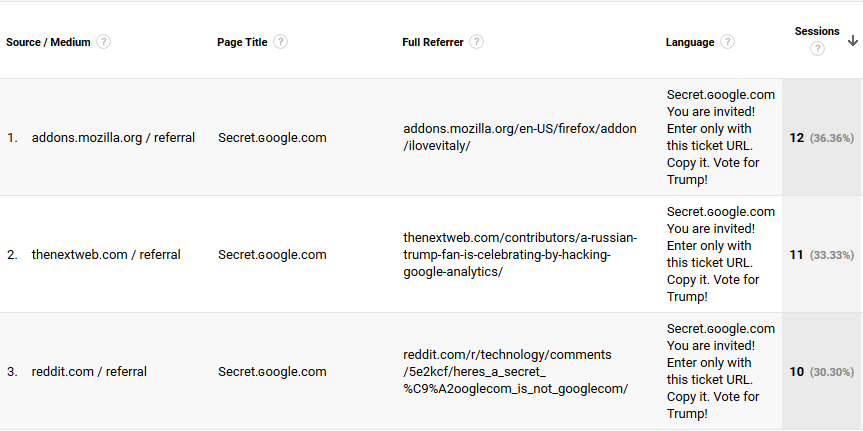
(Update Dec 14, 2016) He later followed up with spam pretending to be from lifehacker, but the domain had small capital “k”, so it was again a phony domain controlled by him. Yet later he started directing users to twitter and blackhatworld, again to threads about his misdeeds. The language dimension featured the text “Vitaly rules google ☆*:。゜゚・*ヽ(^ᴗ^)ノ*・゜゚。:*☆ ¯\_(ツ)_/¯(ಠ益ಠ)(ಥ‿ಥ)(ʘ‿ʘ)ლ(ಠ_ಠლ)( ͡° ͜ʖ ͡°)ヽ(゚Д゚)ノʕ•̫͡•ʔᶘ ᵒᴥᵒᶅ(=^ ^=)oO””.
(I’m leaving him anonymous, although the identity of the person behind the above is known for a while, as I don’t want to give him any more “fame”)
When faced with this situation, I thought:
To Fight Spam, Think Like a Spammer
In movies, we often hear how one needs to think like a criminal to catch one, or to put oneself in the criminal’s shoes. The same is true when it comes to fighting spam. I think it’s about time we stop waiting for Google to fix this and take matters in our own hands, as much as we can.
I’m talking going preemptive on spam.
No, not by using drones to take out the spammers, jeez! I mean going preemptive by deploying anti-spam filters before the spammers even start spamming certain dimensions.
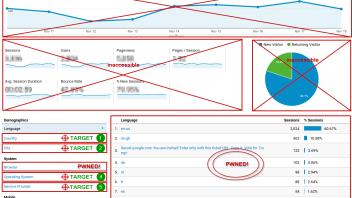
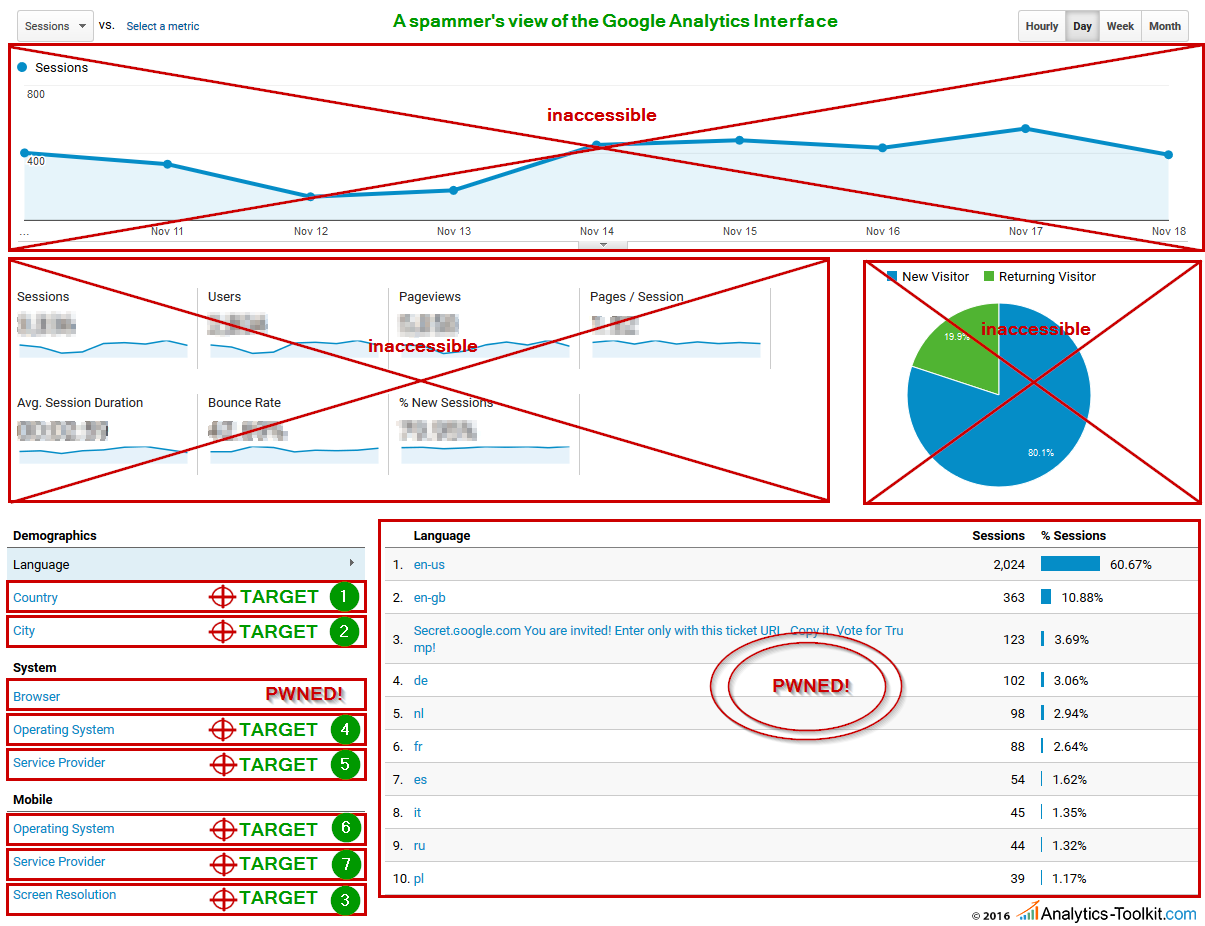
Ask yourself: “If I am a spammer and I want to get in someone’s eyes, what would I do?”. Here is our take on what the Google Analytics home report looks like to a spammer:
(click image for full view)
The most prominent placement for promoting websites already covered (source & medium dimensions), hostname, event tracking and language dimension already abused and the browser dimension beginning to be targeted. The next targets are rather obvious and we’ve even numbered them in the order we believe these would be spammed, if spamming them is possible. We think the Country dimension would be a spammer’s first choice, since:
- many small sites have just a few countries that send traffic to them, making it easy to get to the top 10 with minimal traffic
- the report is featured on the reporting homepage and has a higher chance to be seen
- the report is generally one of the more popular reports to check
- some US and EU sites (the main target of spam) are already filtering out traffic from Russia and other countries in their main views
The forth point is a minor one.
Using this same logic, we ranked the other dimensions featured on the reporting homepage of Google Analytics. We also believe there is good reason to expect the “browser version” dimension will be high on the priority list for spammers. “Viewport Size” or “Browser Size” in the reporting interface, as well as “Flash Version” are also potential candidates, but their popularity is significantly lower and so I believe they would be low on the priority list.
Luckily for us, all geo-ID dimensions, including “Continent”, “Sub-Continent”, “Country”, “Region”, and “City” have built-in validation against a predetermined list of valid locations, meaning no spam is going to make its way inside these reports. This does not prevent a spammer from spoofing (faking) the geo-ID data of his traffic, but it makes it so the dimension is not “spammable”.
However, this still leaves the remaining dimensions, namely “operating system”, “screen resolution”, “browser version”, “service provider”, “browser size” and “flash version” open to abuse. This is in addition to the already abused “language” and “browser” dimensions. And in case you are wondering – yes, all of them can be overwritten when a hit is sent via the Measurement Protocol, which is how most of the spam ends up in your reports!
What I propose and what we will be doing for clients of our Auto Spam Filters tool is to add view filters that either include only traffic with valid data or that exclude traffic with particular types of invalid data. Such filters are to be deployed for a set of dimensions that we identify as likely next targets for Google Analytics spam. Details below:
Future-Proof Google Analytics View Filters
We’ve reached the practical part of this article, where I’ll provide details on what I believe to be proper future-proofing filters that will have a good chance of stopping future spam coming to the dimensions they are applied to. Remember, view filters only work from the moment they are set up, so doing this after the spam is already in will do you no good. You would need custom segments, instead.
Will the filters catch all spam? Probably not, but they should be very effective against spam that aims to point you to a URL by spoofing the dimension value.
If you are already a client of our Auto Spam Filters tool you will get these filters automatically applied as we roll them out in the next couple of days. If you aren’t, but you face the task of adding many anti-spam filters to multiple accounts and views, consider subscribing to our service. Below are instructions for manual application of these filters, with a short explanation.
Note: As always, apply our advice based on your own best judgement and at your own risk. We offer no guarantees about the workings of these filters and take no responsibility for any damages that might be caused by either correct or incorrect implementation of the filters below. Be especially careful if you decide to apply them, but have no prior experience setting up filters in Google Analytics. Even experienced users might want to try these on a test view first. Also remember that it is best-practice to keep an unfiltered “backup” view at all times.
In order to set up any of the filters below you need “Edit” access at the “Account” level in Google Analytics, so make sure you have that, or you won’t even see the setup button.
Filter #1: Language Spam
Yes, it’s not really “future-proofing” as it is already happening and we have another post for that, but for sake of completeness we have the instructions here as well.
The filter I propose will filter out any traffic (hits) where the language dimension contains 12 or more symbols. Since most legitimate language settings sent by browsers are 5-6 symbols and rarely is there traffic with 8-9 symbols in this field, it should only filter out language spam.
There are also symbols which are invalid for use in the language field (based off the ISO standard), but which can be used to construct a domain name (or what looks like it, such as “secret google com”, “secret,google,com”, “secret!google!com”), so we can exclude those as well.
The resulting regular expression looks like this:
.{15,}|\s[^\s]*\s|\.|,|\!|\/
The “Exclude Language Spam” filter can be constructed as shown in the screenshot bellow:
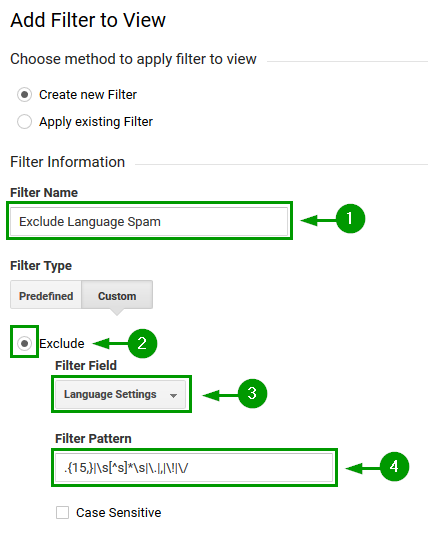
Make sure to filter based on the “Language Settings” dimension.
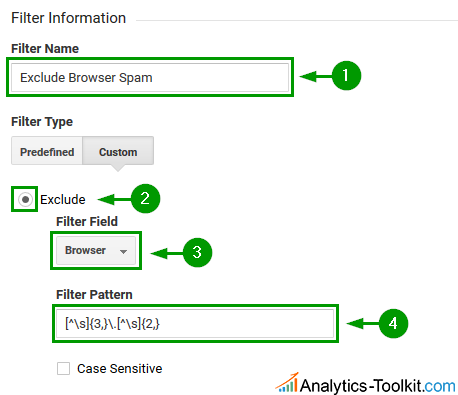
Filter #2: Browser Spam
The filter captures any sequence of 3 or more non-white-space characters, followed by a dot, followed by a sequence of 2 or more letters and looks like so:
[^\s]{3,}\.[^\s]{2,}
Its intent is to capture domain-like strings and since no browser has stuff like “google.com” in their User-Agent string, it shouldn’t cause issue with normal browsers. It will successfully filter out the current spam, e.g. “ɢoogle.com”.
Filter #3: Operating System Spam
The filter pattern looks exactly as filter #2 above, but applied for spam targeting the operating system platform dimension:
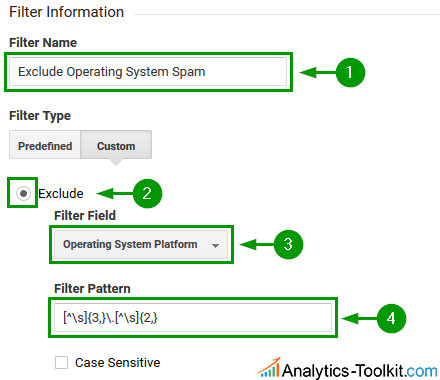
A filter pattern can also be constructed for the operating system version, if desired, but we think it’s very unlikely that this dimension will be spammed so we leave the task of creating a regex to the technically savvy among our readers.
Filter #4: Browser Version Spam
Here we turn straight to an “Include only” filter. Since browser versions have typical structures we can write a regular expression that should capture most valid browser versions, even though we can’t enumerate them all. Browser versions usually contain just numbers and dots between them, as well as the occasional underscore or dash. Some exotic ones used the plus sign as well as letters, but most modern browsers do not deviate from the convention, as the latest exceptions to the rule that we could find with more than a few visits per month date back to 2013. The filter will also include traffic where the browser version is not set at all.
The expression we constructed is:
(^(([0-9]+\.)+[0-9]+|[-_a-z0-9\+\s]+)+|^\(not set\)|^)$
It catches even exotic browsers like Kindle Fire’s Amazon Silk browser, but there is one exception – the Nintendo Browser – version example: “4.3.1.11264.US”. As you can see it’s the .US at the end that matches the regular expression, but there is no way around that. Luckily as far as we are aware it barely sees any web traffic so even very high-trafficked sites see just a couple of visits from it per month, thus discarding them should not be an issue.
With that said, there are no guarantees that a new browser won’t start using wicked browser versions in its signature, but we deem it unlikely to happen.

If you are anxious about applying an include filter, you can try and devise an exclude filter, but it’s harder to get it right due to inherent presence of dots in the browser version.
Filter #5: Screen Resolution and Browser Size Spam
Since screen resolutions and browser sizes are always in one format, so an include filter seems like a very safe bet here. Here is the regex we devised:
(^[0-9]+x[0-9]+|^\(not set\)|^)$
The filter will also include traffic where the screen resolution is not set at all.
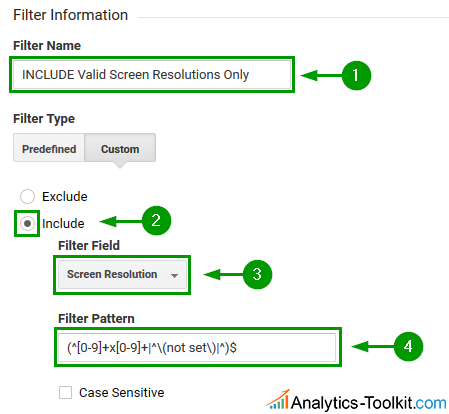
The same filter can be applied to the viewport size, or “Browser Size”, as it is called in Google Analytics.
In Conclusion
I think having these filters should be enough to protect one’s Google Analytics reports for the foreseeable future and I can only hope I am not being too optimistic. Maybe instead of fancy new dimensions being spammed we will instead experience a thunderous return of classic referrer spam, but with more and short-lived domains? Maybe given Google’s immense resources in terms of brainpower and information they will finally figure a way to stop all spam once and for all, despite the inherent issue deep in GA’s operations.
And maybe it’s none of the above and we are yet to be surprised by the turn events.
What are your thoughts on the future of Google Analytics spam and the approach one should take to future-proof their statistics?
About the author

Managing owner of Web Focus and creator of Analytics-toolkit.com, Georgi has over twenty years of experience in online marketing, web analytics, statistics, and design of business experiments for hundreds of websites.
He is the author of the book "Statistical Methods in Online A/B Testing", of white papers on statistical analysis of A/B tests, and has been a speaker at conferences, seminars, and courses. Georgi has been distinguished as a winner in the Data & Analytics category of the 2024 Experimentation Thought Leadership Awards.

Hello Georgi and thank you for your script,
I’m new to script in analytics and trying to understand.
Can you confirm this piece [^\s] means “non white space caracter” ?
I thought it meant “start with a white space”.
Thanks
Djml
This is not a script, this is a regular expression. When in a group “[]” the “^” symbol means negate everything in the group.
This was so helpful, thank you for posting. Will any of these filter out the latest onslaught of copycat referrals – like those from Reddit?
Absolutely, wouldn’t be Future-Proofing otherwise… This is still language spam, so by implementing the advice above or by using our automated tool you will be protected from most language spam to come, including the current latest wave where twitter and blackhatworld are showing up as referrals.
Thanks! Just FYI, Using a regex tester and a sample Analytics language dump I found your original Language regex was matching a bunch of legitimate languages; Removing the `\s[^\s]*\s` option (leaving only `.{15,}|\.|,|\!|\/`) matched only the spam Languages on my list.
We’ve tested this with language stats from many high-trafficked websites and with websites serving different and diverse geographical locations and we’re certain that this should not match legitimate languages as used in browser headers. It’s especially curious to hear that the \s[^\s]*\s part would be causing trouble as there shouldn’t be a situation where the language string contains a blank space, followed by a non-blank and then a blank space again. Two blank spaces are even more out of the question. Would you mind sharing a few examples of legitimate language strings that get caught by this?
When testing your filter in our Analytics, it hits languages with a relative quality factor, like “en-us,en;q=0.5”, due to the comma and the dot in “0.5”. I’m not sure how common these are, so I don’t know how much of a problem this is.
Hi Gorm,
Thank you for your comment. Such language strings should not be registered in Google Analytics, but we did see 3 visits with a language string containing a quality factor in one of the many, many accounts we’ve tested. It’s likely due to a bug or broken headers. The relative quality factor, if present, is stripped automatically by GA since it does not provide any useful information for analysis and will only make analyses harder.
Best
I use a different approach to the language filter. I only include hits from valid languages.
Here my text [edited out: no shortlinks allowed]
I use this >>>
(af|ar|az|be|bg|bs|ca|cs|cy|da|de|dv|el|en|eo|es|et|eu|fa|fi|fo|fr|gl|gu|he|hi|hr|hu|hy|id|is|it|ja|ka|kk|kn|ko|kok|ky|it|lv|mi|mk|mn|mr|ms|mt|nb|nl|nn|ns|pa|pl|ps|pt|qu|ro|ru|as|se|sk|sl|sq|sr|sv|sw|syr|ta|te|th|tl|tn|tr|tt|ts|uk|ur|uz|vi|xh|zh|zu)
What do you think of this approach?
Too easy to circumvent, even without actively trying: many domains and plain texts can have one or more of the two-letter combos in them. Plus, if one is actively trying to circumvent the filter, one can easily write the text send to the language dimension in such a way so it includes one of the two-letter sequences. We tougth of using an inclusion approach, but it’s not possible, because browsers don’t strictly obey standards and there are too many language, country, region, locale and “culture code” combinations to account for them in a regex. Also it’s too risky cause if a new standard is adopted or new language codes, country codes etc. are introduced you’d need to keep track of them and update your filters accordingly – inefficient and too error-prone.
Guys, please advice:
I created this Filter #1: Language Spam
but it doesn’t seem to work for the new language spam about Vitaly…
Is there something that I’ve missed out? Apologies if I’ve misread it and thanks for the help!
Fantastic step-by-step instruction to help keep out spam from GA. Thanks Georgi 🙂