
I’ll start this post right with the punch line:
Internet marketing at its current state is dominated by voodoo magic.
There, I’ve said it, and I’ve said it in bold italic so you know it must be true. Internet marketing is not as data-driven as most of us have been led to believe, it is not as fact-based as you might think and… most specialists are not aware of that fact. Unfortunately, this is not a joke – I can prove it and I intend to do just that in this post. I will also demonstrate how this is hurting the results of everyone engaged in online marketing.
Aren’t Marketers Using Hard Data to Arrive at Conclusions?
In reality – they mostly aren’t. And that’s not just my own experience over the 10 years I’ve worked as an SEO, SEM and web analytics specialist. A 2012 CEB study cited on the Harvard Business Review polled nearly 800 marketers at Fortune 1000 companies and found the vast majority of marketers still rely too much on intuition. And, to add insult to injury – the few who do use data aggressively for the most part do it badly.

Here are some key findings of the study:
Most online marketers rely too much on gut – on average, marketers depend on data for just 11% of all customer-related decisions. When asked about the information marketers used to make a recent decision, they said that more than half of the information came from their previous experience or their intuition about customers. They put data last on their list — trailing conversations with managers and colleagues, expert advice and one-off customer interactions.
A majority of online marketers struggle with statistics – when the marketers’ statistical aptitude was tested with five questions ranging from basic to intermediate, almost half (44%) got four or more questions wrong and a mere 6% got all five right. So it didn’t surprise us that just 5% of marketers own a statistics text book.
The conclusions of this study, which can be rephrased as “Marketers are not much different than shamans”, should definitely attract some attention in the 21-st century, right? I thought such news should have made waves in the industry and in the management circles. Sadly, I was wrong – it barely got any traction. The most horrifying thing is that most of the people commenting on that and similar topics call for some kind of a “unification” between gut feeling/intuition and data. This can mean only one thing – they have no conceptual understanding of what a fact is and how it is established.
Is it really THAT bad?
Unfortunately, yes, and probably even worse than you think.
Try and remember when was the last time you saw the very basic concept of “statistical significance” mentioned in an internet marketing (SEO, SEM, conversion optimization, etc.) case study, whitepaper, blog article or forum post? How many web analytics tools, dashboards or widgets give you such data? Now what about a concept no less crucial than statistical significance – the “statistical power” of a test? What about the “peeking/curious analyst” problem? Do “multiple significance testing problem” or “multiple comparisons problem” ring any bells?
If you’ve never heard those terms you might want to brace yourself for what’s to come, since they are all affecting your decision making processes virtually all the time, no matter if you are doing SEO, SEM, conversion optimization or web analytics in general.
But before we dive into the deep, we need to take a step back and remind ourselves some basic stuff.
How Do We Gain True Knowledge About The World?
The method all knowledge is based upon is called inference. We observe a sample of a given phenomena and based on our observations we infer facts about the whole concept it represents. A simple example: we observe that all objects, if lifted above ground and dropped, fall in a straight line with a given velocity – we correctly infer gravity. On the other hand, we might also observe several tall red-haired drunken men who steal and murder and wrongfully infer that all red-haired men steal and murder.
But how do we avoid making such invalid inferences?
The answer is proper hypothesis test design and proper use of statistics. An example of proper test design would be to randomize our sample and to make it as representative of the whole population as possible. In the example above that would mean including randomly selected red-haired men. This will increase the chance of including sober guys and short guys as well, thus making our conclusion about all red-haired guys much better aligned with reality. If we are more advanced, we would also want to keep the proportions of important characteristics in our observed sample as close to the proportions in the whole population as possible as well.
An example of proper use of statistics would be to calculate the statistical significance of our observed data against a baseline. Statistical significance (often encountered as “p-value“) does not eliminate the uncertainty of our inferences, rather it quantifies it. Thus it allows us to express degrees of certainty that the observed results are not due to chance alone (like the red-haired guys observation). Then it’s similar to a poker game: if you have a better certainty that you have the upper hand, you are happy to bet more on it.
Why Should Online Marketing be Based on Science?
What needs to be understood is that in online marketing we attempt to arrive at a truth statement, usually both explanatory and predictory in nature. Then, based on it we make recommendations and execute specific actions to improve business results. What many people without a scientific or philosophical background fail to understand is that making a truth claim puts them immediately in the realm of science. This means “rational empiricism” and the scientific method is the tool of choice.
The dictionary definition of the scientific method is that it is “a body of techniques for investigating phenomena, acquiring new knowledge, or correcting and integrating previous knowledge”. Put in plain English, it is currently the only proven approach which allows us to distinguish true facts from tricks of the senses and the mind. Integral parts of this approach to objective reality are: solid statistics – for establishing empirical facts, and solid logic – for drawing conclusions and making connections between those facts. The inference example above was a simple demonstration of the scientific method in action.
To the contrary, if you are not using the scientific approach you are in fact engaging in magic rituals. Even when you have the best intentions and a completely unbiased approach, lacking a solid understanding of statistics will often put make you chase the statistical “ghosts” or walk miles towards statistical “mirages”. You have a very good chance of spending a lot of money and efforts, thinking you are making progress while your results are not real.
In the paragraphs to follow I will examine 3 Basic Statistical Concepts every marketer should be intimately familiar with in order to avoid the above pitfall. These are: Statistical significance, Statistical power, and the Multiple comparisons problem.
Statistical Significance
As described above statistical significance is a major quantifier in null-hypothesis statistical testing (THE tool for empirical data analysis and inference of any kind). Most often in marketing we want to test if one or more variations are performing better than a control (ad copy, keyword, landing page, etc.). The default (or null) hypothesis is that what we are doing would not improve things (one-sided hypothesis). Thus in an experiment we seek to find evidence that we can reject this null hypothesis.
When we see improvement in a parameter we are measuring (CTR, CPC, conversion rate, bounce rate, etc.) we can’t simply state that the variant in question is better. This is because our observations are on a limited sample of all of the people who we are interested in. Inferring something for the whole based on a sample is inevitably prone to error. This brings the need to have an idea of how big the chance of error is in our data.
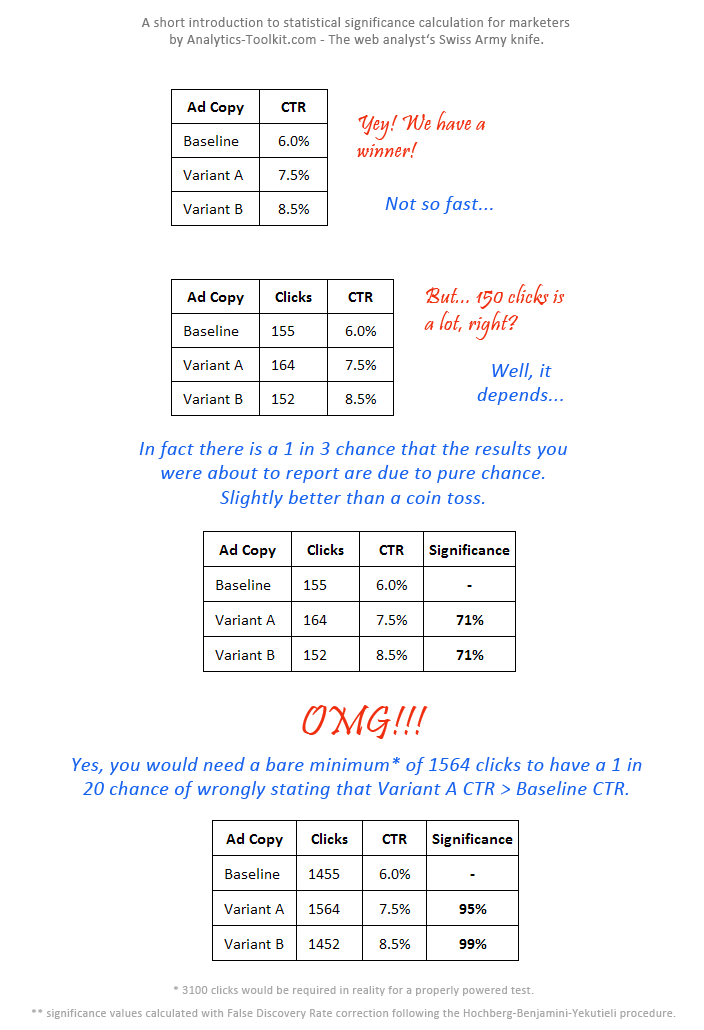
This is where statistical significance comes into play. Having a certain level of statistical significance expresses the likelihood that the difference we observe (or a bigger difference) would not be observed if there was no actual difference. To take a textbook example – having a statistical significant result at the 95% level means that under the hypothesis that there is no difference, there is only a 1 in 20 likelyhood that improvement as big, or bigger than the observed, could have been encountered by chance alone.
The bigger the magnitude of the observed difference, the less data is needed for confirm in a statistically significant way that there is an improvement. The more data we have, the easier it is to detect smaller improvements with a good level of significance.
Here is a more graphical illustration of the whole concept:
It wanted to a sense of how much the industry cares about this most important statistical concept so I did some digging around.
Industry Coverage on Statistical Significance
Avinash Kaushik is one of the first to write about the importance of statistical significance in web analytics back in 2006. LunaMetrics, a major source for web analytics know-how, has only a couple of mentions and just one short recent article devoted to the topic. Even the Google Analytics blog itself has only three mentions of the term in all its years of existence. Their leading evangelist Justin Cutroni has just 1 (one) mention of the term on his blog. On the bright side: KISSMetrics (great innovators in web analysis) have announced just several days ago that they are implementing statistical significance into their reports.
In the SEO corner we have SearchEngineWatch, a major source on SEO and PPC with only 20 articles that mention statistical significance in the past 7 years. SearchEngineLand – another very prominent source has only a couple of articles mentioning significance, the best of which dates from 2010.
The conversion optimization guild currently have the best grip on the topic: VisualWebsiteOptimizer, Optimizely as well as Google’s Website Optimizer had always had statistical significance implemented into the software and have also written about it.
And… that’s pretty much all there is amongst the more prominent sources – sporadic or shallow mentions with a few exceptions. Seems like this topic received very little attention from most of the industry leaders. But why is that bad and what can neglect of statistical significance cause? Let’s examine the most common mistakes made with regards to statistical significance.
Common Mistakes with Statistical Significance
The first and most blatant error is to fail to check for statistical significance at all. Most people fail at this point. One example would be to not wait until a controlled A/B test has achieved a decent significance level (as frequently observed, according to an industry source). Other examples would be to not check for significance when testing Ad Copy performance, when looking at keywords conversion rates/click-through rates in both paid search and SEO, etc.. Needless to say, this leaves us with no objective estimate of the validity of the data we operate with.
Such cases are even present in literature and on very prominent blogs. This example is from a recent post on the VisualWebsiteOptimizer blog which also claims to cite a bestseller book on testing:
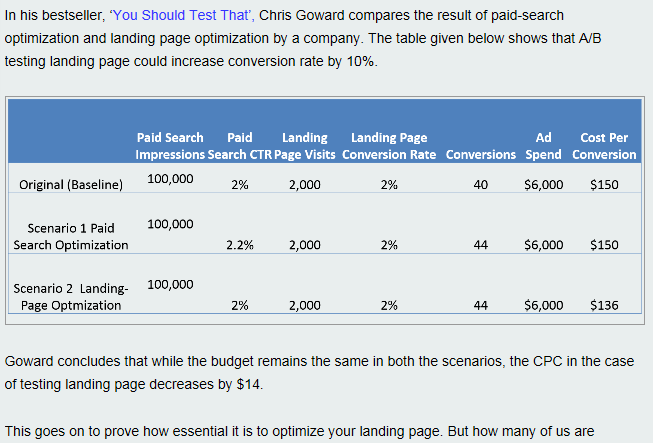
Do you see the problems?
First, the numbers in the table do not correspond to the percentages. Let’s let this one slip and fix the numbers for them. Still, the difference in conversion rates between the scenarios and the baseline are no where near being statistically significant. This means that the registered difference between 2% and 2.2% is most likely non-existent, given the sample sizes. They are indistinguishable. As you can see this is no small error, but a glaring failure in an attempt to use the simplest of data.
Failure to measure statistical significance means that one can invest resources in literary ruining his own business, without even realizing it! From a business perspective statistical significance can be viewed as a measure of the risk involved in making a decision. The more statistically significant the result, the smaller the risk. So, the bigger the impact of the decision, the more you should rely on statistics and the bigger the required level of significance should be.
The second error is to report a statistically significant result but to fail to understand that statistical significance and practical significance (magnitude of the result) are completely different things. Statistical significance only tells us that certainty that there is a difference, it tells us nothing about how big it is! A statistically significant result can have an actual improvement of 0.01% (even if our sample shows a 50% lift).
Here is a quick example:
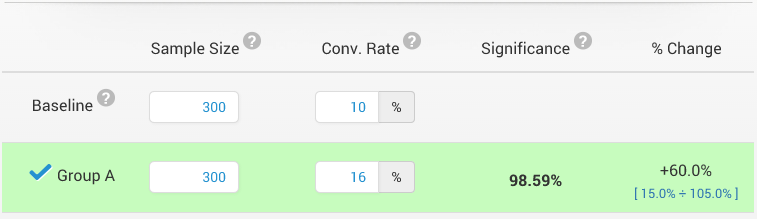
The achieved statistical significance is very high, but notice the blue numbers in the “% Change” column. They tell us that even though the improvement detected in our test is 60%, the actual improvement we can predict with 95% confidence, given the current data, is anywhere between 15% and 105%, with all values equally likely!
An infamous case of such neglect is a highly cited SEOMoz study on SERP ranking factors. The study claimed significant results where obtained that showed how different SEO factors correlated with SERP ranking. However, it failed to inform that even if the results were statistically significant they were in practice negligible in magnitude and didn’t support their claims for alleged signals correlation to SERP rankings. There were no real findings in this study, the level of correlation was miniscule. Detailed discussions on the issue can be found on Dr. Garcia’s blog here and here, as well as on Sean Golliher’s blog for computer science and AI here.
This type of false conclusions lead to overestimation of the achieved results, thus – the potential benefits. A cost/benefit analysis flawed in such a way can have terrible consequences.
The third error is to interpret a statistically insignificant result as support for lack of difference/lack of effect. This is where I need to introduce
Statistical Power
Statistical power is related to the number of visits or impressions (sample size) you draw conclusions from, and the minimum improvement you care to detect. On one hand power defines the probability of detecting an effect of practical importance. The higher it is, the better the chance. On the other hand, the power of a test can have a great effect on statistical significance calculations to the point of rendering them worthless.
There are two ways to get power wrong: to conduct an underpowered or an overpowered test. A test is underpowered if it has inadequate sample size to detect a meaningful improvement at the desired significance level. A test is overpowered if it’s predetermined sample size is inadequately large for the expected results.
Statistical Power Mistake #1
The first thing that can happen with an underpowered test is that we might fail to detect a practically significant change when there actually is one. Using such a test one would conclude that the tested changes had no effect, when in fact it has – a false negative. This common mistake wastes a lot of budgets on tests that never receive enough traffic to have a proper chance to demonstrate the desired effect. What use is running test after test if they have inadequate sample size to detect meaningful improvements?
In an infamous use of underpowered tests in the 1970s car drivers were allowed to turn right on red light after the several pilot tests showed “no increase in accidents”. The problem was that they had sample sizes too small to detect any meaningful effect. Later, better powered studies with much larger sample sizes found effects and estimated that this decision in fact claimed many lives, not to mention injuries and property damage.
Statistical Power Mistake #2
The second thing that might happen with an underpowered test is that we increase the chance to detect a statistically significant (and often practically significant) result where there is none. The probability of committing such an error is correctly described by the significance level when the sample size for each group is fixed in advance. Fixing the sample size is done on the basis of the desired significance level and the desired power. Checking for statistical significance only after a test has gathered enough the required data shields you from such an error.
Failing to do that and stopping a test prematurely (before the required numer of impressions/visits, etc.) greatly increases the likelihood of a false positive. This is most commonly seen when one checks the data continuously and stops it after seeing a statistically significant result. Doing this can easily lead to a 100% chance to detect a statistically significant result, rendering the statistical significance values you see useless. Hurrying to make a call and stop a test as soon as a significant result is present is counterproductive.
Here is an actual example from CrazyEgg’s efforts in A/B testing:
“When I started running A/B tests on Crazy Egg three years ago, I ran around seven tests in five months. The A/B testing software showed that we boosted our conversions by 41%. But we didn’t see any increase in our revenue. Why? Because we didn’t run each test long enough…”
Reading further in Neil Patel’s blog post reveals that the issue he was experiencing was exactly the “premature stopping based on significance” issue above (his reasoning about how to avoid it isn’t correct, though). If we fall prey to the above error we might run one “successful” test after another and pat ourselves on back while at the same time achieving no improvements, or worse – harming business. I think many of us have been there and have implemented a “successful, statistically significant” test variant only to find out a few weeks or months later that the effect is not what we’ve estimated during the test.
As Prof. Allen Downey puts it in this excellent post: “A/B testing with repeated tests is totally legitimate, if your long-run ambition is to be wrong 100% of the time.”. NOT fun.
Here is a more detailed illustration for the second mistake with statistical power:
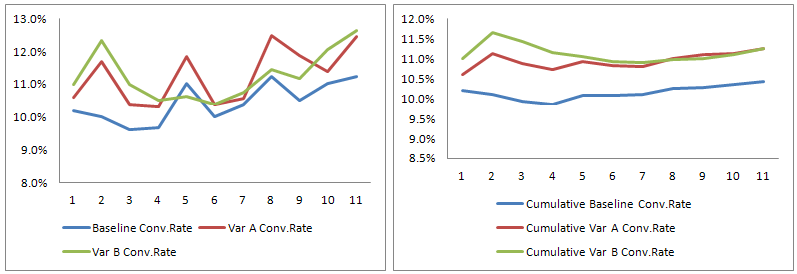
If we had the conversion rate data per variant as above, from the first 16 days of an experiment, and we had 95.9% statistical significance for the difference between the baseline and variant B at the end of day 16, should we declare B the winner and stop the test?
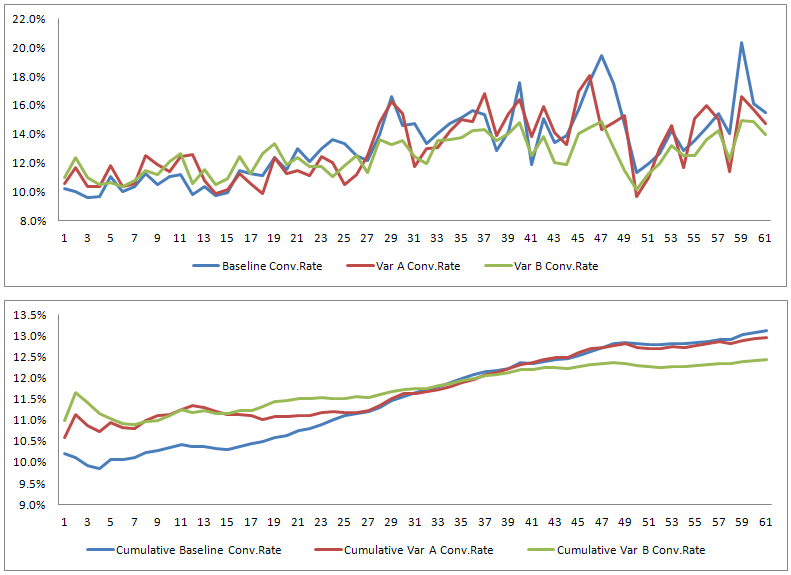
Here is the full data for the test – 61 days (the horizontal scale). On the left vertical scale you see the conversion rate percentages. The orange line is the statistical significance for variant B against the baseline (cumulative, right vertical scale). The two grey horizontal lines represent the 90% and 95% levels respectively.
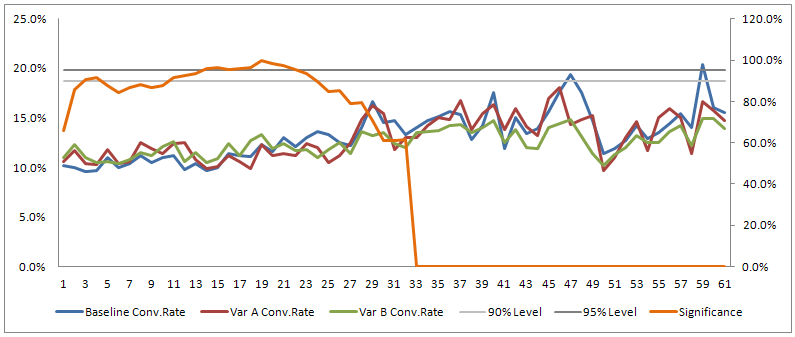
If you choose the 95% level and you only wait for significance, without waiting for achieving the preset sample size, you would wrongly select variant B if viewed the test results between day 16 and day 22. For a 90% significance level you could have identified a false positive as early as days 3 and 4, as well as between day 11 and day 23. In the above example our test fails to produce a winner by day 61 since all variants regress back to the norm (bonus points if you noticed that the first two graphs are not zero based).
This example demonstrates why it’s important to wait until a test has reached a sample size where it has enough power. Since the issue here is “peeking” on the data and actually doing a statistical significance test on each day, this is also a custom case of the “multiple significance testing” problem that I discuss in detail bellow.
Unfortunately, such mistakes have been and likely are still encouraged by some A/B testing tools, so I would like to end the part on optional stopping with this quote from Evan Miller:
If you write A/B testing software: Don’t report significance levels until an experiment is over, and stop using significance levels to decide whether an experiment should stop or continue. Instead of reporting significance of ongoing experiments, report how large of an effect can be detected given the current sample size. Painful as it sounds, you may even consider excluding the “current estimate” of the treatment effect until the experiment is over. If that information is used to stop experiments, then your reported significance levels are garbage.
Statistical Power Mistake #3
Finally, in case we overpower a study we are most likely wasting money and other resources when we’ve already proven our point beyond the reasonable doubt we are willing to apply. I won’t go into further detail here and leave this for another post.
Industry Coverage on Statistical Power
Given all that I expected statistical power to be discussed at least as much as statistical significance. However, the mentions of statistical power are virtually non-existent in the most prominent blogs and sites that deal with internet marketing. Evan Miller was one of the first to cause some waves in the conversion optimization community with his 2010 post How Not to run an A/B test which tackles the issue of statistical power.
VisualWebsiteOptimizer is the other prominent source on this topic. They have quite a few mentions on their site and blog, with this post deserving a special mention. On the downside – they have a huge number of case studies featured on their site with only half of them containing information about the statistical significance of the result. I didn’t see statistical power being mentioned in any of them.
Optimizely only mentions statistical power in an obscure location on a long page about “chance to beat original” in their help files. This post by Noah from 7signals – determining sample size for A/B tests is another decent one I was able to find.
A good whitepaper by Qubit titled Most winning A/B test are illusory (pdf) inspired the guys at KISSmetrics. They did a decent article on the topic available here. However, when announcing the release of statistical significance reporting in their tool a few days later they failed to mention “statistical power” in that post.
Not only is “statistical power” a foreign concept to the industry, but even in articles that attempt to explain statistical significance (e.g.: ones titled “A Marketer’s Guide to Understanding Statistical Significance” and the like) power is commonly misunderstood and the lack of significance is said to mean lack of difference (mistake #1 above).
On Using Online Sample Size Calculators
Be careful about the following common peculiarities:
First, most, if not all of them calculate the sample size for a two-tailed hypothesis. Thus they are overestimating the sample size required to detect the desired effect when we are only looking for improvements and are not concerned about the precision of results that are worse than the baseline. Following their recommendations would result in wasted budgets for generating traffic/impressions.
Second, some only calculate based on a 50% baseline, which is useless for online marketing where we have varying baseline rates to work with. Finally, some others (e.g. CardinalPath’s free calculator) are reporting at a fixed power of 0.5 or 50%. Hence the chance to miss a significant result at the desired level of improvement is 1 in 2, too high for most practical applications.
In Analytics-Toolkit.com‘s calculator we’ve attempted to present a flexible solution that should fit most people’s needs properly.
Now that we have our significance and power right, let’s tackle the toughest of the four:
The Multiple Comparisons Problem
The multiple comparisons problem arises each time you study the results of a test with more than one variation by comparing each against the baseline. Put simply: the more we test for the same thing, the more likely we are to falsely identify a result as significant when in fact it isn’t. The more test variations we create, the more likely it is that some of them will demonstrate statistically significant results when there is no discovery to be made. This is one reason why marketers who test more variations per test report (falsely) much more and much better results than expected.
For example: we have a baseline AdWords keywords conversion rate and we are trying to find one or more keywords that outperform the baseline in a statistically significant (and sufficiently powered) way. To do this we decide that we want to be 95% certain and begin comparing the conversions rate of each of 13 keywords to that of the baseline, looking for one that would show an improvement at the chosen level of statistical significance.
If we were only running one keyword and needed to check only that keyword against the baseline, we would have been fine. However, if we have 13 keywords and we check all of them against the baseline, things change. If we get one significant result at the 95% level and decide to direct more of our budget to that keyword, that would be wrong.
Let me demonstrate why. Settling for 95% statistical significance means we are comfortable with a 1 in 20 probability that the observed change in the conversion rate is due to chance alone. However, looking at those 13 keywords’ conversion rates via pairwise comparisons to the baseline would result in that we would have about 50% chance that 1 of those differences in conversion rates shows up as statistically significant while in fact it isn’t. This means we would have a false positive among those 13 keywords pretty much every other time.
What this means, of course, is that the 95% statistical significance we are going to report for that keyword is in fact not 95% but significantly lower. This is not at all limited to marketing, pardon me. Some shocking papers have come out lately stating that “most published research findings are false“. If you are into comics, xckd has this awesome comics on the issue.
The desire to avoid those false positives is what justifies the need to adjust the significance values for those pairwise comparisons. We can do so based on the number of the tests conducted/variants tested, and their results in terms of significance.
I would argue that for practical applications in the internet marketing field the False Discovery Rate correction method is the most suitable one. With it we apply a correction to the significance level of each variation or group in order to estimate the true statistical significance when a multiple comparisons scenario is present.
Here is a simple example with only 3 variants (increasing the number of variants only increases the problem):
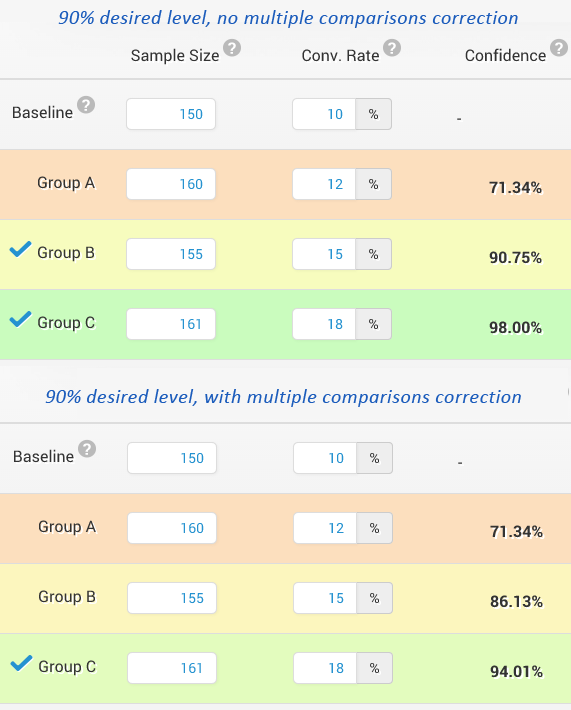
The differences in significance levels with and without correction are obvious. Bonus points if you’ve noticed that the above statistical significance calculations are likely prematurely stopped (underpowered) 😉
Virtually all tools that report statistical significance that I’ve looked into did NOTHING to correct for the multiple comparisons problem
Even the otherwise good Qubit paper I’ve mentioned above fails to grasp multiple testing properly. It mentions it is somewhat of a problem, but doesn’t mention any significance level adjustment/correction methods. Instead, it recommends keeping test variants to a minimum and sticking to what is expected to provide significance effects.
While I won’t suggest that we engage in pointless scattergun approach to testing, I think multiple variants testing is a completely fine approach when done properly. In conversion optimization we can usually limit the number of tests we do, but it is often impossible (and incorrect) to limit the number variants/groups analyzed when doing observational studies. For example if we are examining different characteristics of multiple traffic sources and their performance. Remember, working with a non-randomized subset of the available data on an issue is often cherry-picking.
Most Statistical Significance Calculators are Useless or Flawed
Given the above issue, I deem it fair to say that all free online statistical significance calculators and Excel sheets that I’m aware of are either useless or flawed. Most of them only calculate significance for one variations against a baseline. Thus they are impractical for actual usage, as most often we need to compare several ad copies or several landing pages or many traffic sources, keywords etc. when looking for ways to improve their performance. As explained above, using such a calculator and doing multiple pairwise comparisons opens you up to a much higher error than the one reported by the calculators.
Other calculators work on one baseline and several variants. That’s better, but most do not even try to correct for multiple comparisons and this can have visible effects even with only three variants, as demonstrated above. There is one attempt I know of to make a good significance calculator that works on many variants and corrects for errors introduced by multiple comparisons. However, its correction method (Dunnett’s) is unnecessarily strict for practical applications.
Thus the only calculator I know of that handles multitude of variants and corrects in a practical manner for errors introduced by multiple comparisons is currently our statistical significance calculator. It was used to produce the example above.
Enough, I Get It! But What To DO About All This?
I understand it might have been hard for many of you to reach this far into this post, but if you did: congratulations, you are one tough marketer!
So here is what I think you can do if you are passionate about improving the quality of your work through real data-driven decisions:
#1 Learn about experiment design and hypothesis testing. Apply the knowledge in everyday tasks.
#2 Learn about statistics and statistical inference, and apply the knowledge in everyday tasks. Things to avoid: Bayesian inference, the Bayesian statistical approach (nothing against the Bayes rule itself).
#3 Demand better statistics from your tool vendors. Reach out and let them know you care about good data and good decisions. They will listen.
#4 Educate your boss, your customers and whoever else benefits from your work about your newly found superpower and how it can work for them.
An awesome quote is due: “Being able to apply statistics is like having a secret superpower. Where most people see averages, you see confidence intervals. When someone says “7 is greater than 5,” you declare that they’re really the same. In a cacophony of noise, you hear a cry for help.” (Evan Miller)
In this blog we will try to help with #1, #2 and possibly indirectly – for #4, by publishing more (shorter!) follow-up articles like this one on the Simpson’s paradox in online marketing. They will cover some of the concepts in this article more thoroughly, there will be posts on how to setup a test properly, how to choose significance and power levels, sequential testing, analyzing data in Google Analytics or Google Adwords and basically everything that has to do with statistics and online marketing. Our first pieces will likely be on how to choose your power and significance levels, so stay tuned!
Afterword
I started writing this post with a great deal of excitement, because I’m really passionate about good marketing for good products & services and I am passionate about achieving real results with what I do.
The purpose of this post is to raise awareness of what I consider to be crucial issues for the whole internet marketing industry and for everyone relying on our expertise. I believe I’ve successfully proven there are issues and I’ve shown how deep those issues go, how pervasive they are and how dangerous their impact is. I think I’ve made a strong case as to why every marketer should be a statistician. Let me know if you agree or disagree with me on this.
I’d like to cite another insightful thought from Evan Miller:
One way to read the history of business in the twentieth century is a series of transformations whereby industries that “didn’t need math” suddenly found themselves critically depending on it. Statistical quality control reinvented manufacturing; agricultural economics transformed farming; the analysis of variance revolutionized the chemical and pharmaceutical industries; linear programming changed the face of supply-chain management and logistics; and the Black-Scholes equation created a market out of nothing. More recently, “Moneyball” techniques have taken over sports management…
If you want to help raise the awareness about these issues and thus turn internet marketing into a better, more fact-based discipline, please, spread the message of this article in any shape or form you see fit. And I appeal to all online marketing tool vendors out there – please, try and make it easier for your users to base their decisions on facts. They’ll be grateful to you as whoever has the better facts has a better chance to succeed.
Update June 2017
After exploring the topic further, I’ve come to the conclusion that the main reason behind many of the misapplications of statistical tests is the fact that the tests used are simply not suited to the use-case in A/B testing. Thus I searched for best practices in fields where similar stimuli operate and so I stumbled upon medical trial design and statistical evaluation. From it, through tedious process of R&D, the AGILE A/B testing statistical method was born. It is too long a topic to cover in a blog post, so I’ve written a complete 46-page white paper, available for a free download on our site. If you liked the above article and want to do scientifically-based A/B tests with a statistical method that is suited for the case, make sure to try our new A/B Testing Calculator which makes applying the AGILE approach easy and fun!
Georgi Georgiev
Founder @ Analytics-Toolkit.com
Full disclosure: This article contains “popular” usage of some statistical terms, particularly “significance” and “certainty”, in order to make them more accessible to the general public.
About the author

Managing owner of Web Focus and creator of Analytics-toolkit.com, Georgi has over twenty years of experience in online marketing, web analytics, statistics, and design of business experiments for hundreds of websites.
He is the author of the book "Statistical Methods in Online A/B Testing", of white papers on statistical analysis of A/B tests, and has been a speaker at conferences, seminars, and courses. Georgi has been distinguished as a winner in the Data & Analytics category of the 2024 Experimentation Thought Leadership Awards.


{kind=link}
{kind=link}
Thank you for the quote. More on the topic here:
http://irthoughts.wordpress.com/2013/12/06/why-most-seo-statistical-studies-are-flawed/
In particular, notice that standard deviations, correlation coefficients, cosines similarities, and slopes, among others, are dissimilar ratios, and therefore are not additive. These are things many SEOs fail to understand. I wrote a peer reviewed article on the subject for a statistical journal here (Communications in Statistics – Theory and Methods; Volume 41, Issue 8, 2012 ):
http://www.tandfonline.com/doi/abs/10.1080/03610926.2011.654037
Thank you for your comment Dr. Garcia. In the article I linked to your other posts on the topic as I fear the concepts outlined in the post you link to are far too advanced for the average reader this article is intented for.
Your study also looks interesting, thanks!
Interesting article. Considering that most small businesses don’t have huge budgets for online advertising and even tighter budgets for data analysis, I’d love to see some real world data about what works with online advertising. Now that you’ve shown us what doesn’t work, lets see what does!
Hi Elliott,
Indeed, many SMBs have limited budgets, but this also means there is less data to analyise so sufficient analysis would be much cheaper. Thus a small budget should not stop most of them from using simple statistical concepts as the ones outlined above. SMBs will have different requirements for significance levels and power, based on their cost/benefit estimates, but it all applies to them nontheless.
I will do follow-up articles with advice on how to apply statistics in with a good cost/benefit ratio in different situations.
Your discussion above is very good. The data and supporting graphs are very useful.
A main concern with SEOs is that they often follow pretty ideas that by all means are useless. Consider the question of additivity. If something is not additive, it cannot be averaged in the arithmetical sense either. This is true for correlation coefficients, standard deviations, cosine similarities, etc. Yet, some of the big SEO firms and web analytic companies just do that because they have heard in some SEO places that you can do that. The end results are “studies” that are just “quack science” to say the least.
Hi Georgi.
Interesting article on a crucial subject. I completely concur with the title and the assertion that “Internet marketing at its current state is dominated by voodoo magic.”
However, I am very suspicious of statistical significance testing and, more so, of A/B Testing.
Many statisticians consider Stat Sig tests today as not fit for purpose. A professor of statistics at Columbia told me “you can find statistical significance in absolutely anything if you want to.”
Certainly, the bigger the sample the more likely you are to find Stat Sig.
My problem with A/B testing is that, by definition, it compares only two data points and there’s no reason to expect them to be identical.
I ran a series of 20 A/A tests (ones where the “variants” were exactly the same), on a mix of emails and web pages, all with large samples (e.g. 61,000 visits over a 34 day period).
In exactly half the tests, I got “statistically significant” differences in the results. This points to an underlying variation that had nothing to do with subject lines, design of web pages etc.
If that is the case, how can you trust an A/B test when it gives you similar results? Any difference detected (no matter how robustly) could be due to the changes you made or to something else entirely.
Cause and effect can be inferred but is it correct?
What are your thoughts on that (and have you ever done extensive A/A testing)?
Thanks.
Simon
Hi Simon,
Thank you for you comment.
About your suspicion of ‘statistical significance”: The framework of sample testing/severe testing/error statistics is currently the best we have. This includes statistical significance as one of the tools. Care to show otherwise and propose a better framework? I guess a lot of scientists around the world would be grateful.
About running A/A tests: Yes, of course, you can run series of A/A tests with large amounts of subjects/visitors/impressions etc. and you will always find difference in performance that is statistically significant at a certain level (95%? 99%? 99.99%?). If you have unlimited budget to waste, that is.
This is so because you are sampling and that means there will be sampling errors when making inference from the samples about the whole. This is what significance levels are for, after all, to estimate those errors. From this point of view doing A/A testing is simply useless. We already know that our two samples would be different, even when coming from the same sampling space. Why would you want to waste money on establishing a known fact?
I might actually do a post solely about that, given the widespread confusion I see on this topic as well.
Some other remarks that might be interesting for you, which are not limited to A/A tests:
The bigger the sample size you need to reach a certain significance level, the smaller the difference is, the less severe the test is. If you have 61 000 visits and reach 95% statistical significance for the difference between A and A then the detected difference would be absolutely miniscule, like several positions behind the decimal point (relatively!) e.g. 0.01% or 0.001% improvement or less, depends on the baseline. Such differences are meaningless for most if not all practical online marketing purposes I can think of.
Finally – have you fixed your sample sizes in advance? Or are you using a sequential testing correction for the p-value? If you are doing neither, then your “observed significance” matters not (is fake).
Thanks for replying Georgi.
I’m not a statistician sadly, just a small boy to whom it appears the Emperor has no clothes (or perhaps I just need my eyes testing).
You seem to be arguing for a more thorough methodology for testing.
My suggestion takes a different tack and is that A/B testing, in particular, is not helpful to marketers because, no matter how robust the mathematics, you still have to make an inference for what caused any difference detected.
All the most robust methodology can do is show that there’s a difference between two numbers (or not); it can’t tell you why.
A/A testing can at least show that the “cause” may have nothing to do with subject lines or size/colour of buttons and making that connection is very possibly erroneous.
How do you feel about measuring the variation in a process (through something like Shewart control charts) both before and after a change is made? Seasonality and other time-related variables have to be factored in but shifts in data can indicate whether the change has had an effect or not. You still have to make an inference (there could be other coincidental correlated factors making it happen) but you learn more than by just comparing the results of two samples run simultaneously.
“You seem to be arguing for a more thorough methodology for testing”
I don’t argue *for* a more thorough methodology than sample testing. I was under the impression that it is you who has an issue with statistical significance.
I fail to see how A/A testing shows us anything we don’t already know – that sampling is inherently error-prone and taking two samples from the same distribution would always result in different sample statistics. A/A testing tells us nothing about the cause, it simply tells us there is difference which we already know, otherwise the need for statistics is immediately gone.
About measuring the variation:
In my view seasonality, time-related factors and other confounders are accounted for in a stardand A/B test, given that the test is properly randomized. I don’t see the need for additional work in this direction.
As far as Shewhart’s control charts – this is a tangent I am not familiar with, but from a cursory reading it appears to concern a different case entirely. As far as I understand it’s a process for measuring variability and ensuring stability for production lines. So it’s basically as if we are analysing just one variant over time and checking every several visitors to see how stable the performance is based on a given metric. How such a method could help A/B testing is beyond me, but certainly feel free to educate me or point to relevant readings if I’m missing something here.
PS Given your defence of the long established practices of scientists all over the world, I take it you feel that the assertion that “most published research findings are false” is incorrect? (That’s a question; I’m not trying to put words into your mouth).
I just think that, given the growing dissent about scientific research methods, it’s good to have a healthy scepticism towards such methods, taking into account that most researchers want to be published and no-one publishes or publicises negative findings, selective reporting is common etc.
I am not really looking forward to becoming a scientist in the strict sense, nor do I have the full expertise the judge the above, but my humble understanding of the issue is that the statement “most published research findings are false” is not true. Which is, of course, far from saying that the applications of certain aspects of scientific and statistical methods is flawless or exempt from errors. To the contrary, I believe that what plagues internet marketing is also present in science, but not to the extent where one could state the above, and certainly not because of the Ioannidis paper and several similar ones.
Here are some readings you might be interested in:
http://scienceblogs.com/insolence/2007/09/24/the-cranks-pile-on-john-ioannidis-work-o/
http://errorstatistics.com/2014/05/20/the-science-wars-the-statistics-wars-more-from-the-scientism-workshop/ (slide 43-46)
http://errorstatistics.com/2013/11/09/beware-of-questionable-front-page-articles-warning-you-to-beware-of-questionable-front-page-articles-i/
http://simplystatistics.org/2013/12/16/a-summary-of-the-evidence-that-most-published-research-is-false/
http://normaldeviate.wordpress.com/2012/12/27/most-findings-are-false/ (with some reserves, but still, even Bayesians come to the same conclusion).
There are really much better prepared people to have a debate over that topic (philosophers of science, statisticians, etc.) and I don’t think this article’s comments are a good place to do have such a debate 🙂 However, you can reach me via our Contact form and we can exchange contacts if you want to engage further with me on this.
“A/A testing tells us nothing about the cause, it simply tells us there is difference which we already know”
Of course it doesn’t tell you about the cause but it demonstrates that there are differences even when no changes have been made.
And A/B testing doesn’t tell us any more – just that there is a difference (which we should also already know). How does that help us in knowing whether one subject line or web page layout works better then another?
The relevance of control charts, as I see it is, is that you understand the variation that exists in a stable system, you then make a change and can see if the data behaves differently. If you change your web layout for instance and you see a shift in the data over a number of data points following the change, you can infer that the change made a difference. You can then continue to monitor over time to see if the shift is ongoing. The shifts are based on the standard deviation, so give much more information than a simple run chart where you can’t see whether the shifts are significant (especially if the variation is wide).
All A/B testing does is tell you that your two samples behave differently (which is exactly what you’d expect).
Thanks for your time on this.
No, that’s not what I said. The difference is between the samples, not between the hypothesis (variations) being tested, which I stated explicitly several times already: in my previous comments and immediately before the sentence you cite and which it builds on. So A/B tests certainly do help gain new knowledge. A/A tests don’t.
“All A/B testing does is tell you that your two samples behave differently (which is exactly what you’d expect).” – can’t agree here. An A/B test will sometimes tell you that your variant do not perform differently (in a practically meaningfull way), other times they’ll tell you that you can be X% certain that your variant is underperforming or overperforming by a given percent. It allows you to do so in a cost efficient manner (visits/clicks, etc. are not free) and while knowling your margin of error.
About control charts – I don’t see how standard deviation measures give any more information than a p-value, given that a p-value is actually a direct derivative of SD sigma measurement. I have found one paper discussing usage of control charts in in A/B testing but it is so bad that I hope you are not drawing your info from it (by Scott Burk, Marketing Buletin 2006, issue 17). It basically says this:
– run variation A for X days/X visitors
– then run variation B for X days/X visitors
Then see if there is difference. Well, if this is the process you propose (you mention “data points following the change”, so I assume it is something along those lines) then that is exactly the kind of process that is open to all kinds of confounding variables, including seasonality/time-related factors. Inferences based on such a process would suffer from extreme issues. A/B testing as it is is not affected by such problems so if I got you right, I have to say the control charts method is definately inferior.
Feel free to correct me if I am wrong. I’m struggling to find good info on the topic.
Hey,
great post, except for the flaw that it doesn’t offer an alternative.
I for my part have been seeing this problem for a while and for the most part rely on best practice and my gut feeling for lack of a good alternative.
In most cases one simply lacks data to get good data.
The other thing is that customers want to see their agency do something for their money. A company with a certain marketing allocation hires people to do things and don’t want to see employees loafing, even though it would be better to loaf and wait for data.
I tried recruiting new customers based on teaching them who things work, little results. Then I just blindly recruited them with wild promises etc… and it works.
People are not interested in the right actions, they just want to do something.
Right now we are riding the wave of conversion optimization, yesterday it was something else and in the future it is going again something else.
Most companies spend most of their time and energy on actions not production related. Marketing, bookkeeping, quality controlling, personnel and what not. A/B testing is at least creative.
Hey Steven,
Coming up with a good diagnosis when few people around you seem to be able to do it is still quite a fine act (I’d argue) 🙂 I agree that the article doesn’t offer a solution and that was not its aim as it is already 2500 words+ even without a solution in it. Let me tell you – I’m slowly working towards a good solution and others are working on solutions as well. For example just in the past several months both VWO and Optimizely launched their own solutions to the problem based on significantly flawed Bayesian approaches. They might still be a slight improvement over the current situation, but I can’t judge that based on the info I have so far.
And if there are people not interested in the right actions – then this post is simply not for them. This post is for people who want to take the right actions and who will ultimately drive the businesses who are not doing the right things out of the market…