
In this article, I explore the concept of non-inferiority A/B tests and contrast it to the broadly accepted practice of running superiority tests. I explain where non-inferiority tests are necessary and how a CRO/LPO/UX testing specialist can make use of this new approach to A/B testing to run much faster tests, and to ultimately achieve better results for himself or his/her clients.

Let’s start with something “simple”: why do we care if the result of an A/B test is statistically significant?
The answer seems obvious enough: we don’t want to look like fools, claiming something improves conversion rate (or CTR, or e-commerce transaction rate, etc.) when it does not, or in fact it does the exact opposite. We want to be able to justify the work we do and to claim credit for the positive impact of our actions or advice as CRO practitioners. For the above reasons, designing A/B tests with proper statistical methodology and accepting a new variant only when it passes a particular statistical significance threshold is a must.
The choice of null hypothesis matters (a lot!)
A/B testing practitioners must never forget that statistical significance is a only a part of the broader process of null hypothesis statistical testing, hence the statistical significance of a test depends heavily on what statistical null hypothesis is chosen. This stems from the very basis of experimental design, as in the words of R.A. Fisher:
“Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.” [1]
Here is a quick practical example. Say we have observed two groups of 4,000 users each in a randomized controlled experiment. The control converts at 10%, the variant at 11%, a 10% observed relative improvement. Is the result statistically significant at the 95% level, with a one-sided z-test?
No one can answer that question! What is missing from it is the null hypothesis. With a “classical” null hypothesis of “the difference between the variant and control is 0 or negative”, the answer is “no” (z-value corresponds to 92.77% significance). However, with a null hypothesis of “the variant is 2% worse than the control, or more”, the A/B test becomes significant at the 95% level (96.6%) with the lower bound of a 95% confidence interval for the difference in proportions at -1.3%.
What happened above? When the question asked (expressed in terms of null and alternative hypotheses) is different, the answer is, naturally, different as well. The first hypothesis is a superiority test: we want to ward against the error of implementing a new solution, thinking it is superior to the current solution, while in fact it is not. The second one is actually a non-inferiority test: we wanted to ward against the error of implementing something that is significantly worse than the current solution – in this case the “margin of caring” was set at 2% negative difference. With the first null hypothesis, we would have guided our decision in one direction, with the second: in the opposite one, even though the data is exactly the same!
Therefore, it is very important to select the right hypothesis when planning the statistical design of any A/B test. Below I explore the logic behind the choice of superiority and non-inferiority null hypothesis and the costs and benefits of choosing one or another.
When to test for superiority?
In all the A/B testing literature I’ve read and all case studies I’ve seen, the null hypothesis, where it is specified or can be inferred, is that the control is performing worse than or equal to the tested variant:
Null hypothesis: variant(s) ≤ control
The above is called a superiority design or a superiority A/B test. With a such a test we declare that we will act with the presumption that:
The error we want to avoid the most is the error of implementing a solution, which is not better than what we currently have
This makes perfect sense when the proposed new solution, or solutions:
- has high implementation costs, outside the cost of running the A/B test
- requires ongoing maintenance / recurring costs (IT infrastructure, support, 3-rd parties involved, etc.)
- is costly or impossible to reverse, once it is implemented (technological, PR, marketing, etc. reasons)
- faces strong internal or external opposition from HiPPOs, stakeholders, etc. for other reasons
When calculating sample size based on a desired statistical power, we need to select the smallest difference we would be happy to detect – the minimum effect size. This discrepancy is usually small, with common values between 2% and 10% relative lift, since for most A/B tests detecting such discrepancies is enough to justify running the test, and to implement and to maintain the winning variant. However, it is not always as small as we would like, since sometimes we just can’t push enough users through the test in a reasonable amount of time.
If the minimum effect of interest is selected objectively and we have one of the above cases, then testing for superiority is justified and should lead to the best possible outcomes.
The need for non-inferiority A/B tests
At first thought, it makes perfect sense to design all A/B tests as superiority tests. After all, why would you want to implement something that is not proven better than what you currently have?
However, there is a flaw in the above logic and it stems from lack of understanding of statistical power. Statistical power is the sensitivity of the test. It quantifies the probability to detect a difference of a given size with a specified statistical significance threshold, if such a difference truly exists. The greater your sample size, the greater the power of the test, everything else being equal. However, the smaller the margin you want to be able to detect, the lower the power of the test. Thus, even if you have the most-trafficked site on the internet, your A/B tests will still fail to detect many true, but small improvements, as statistically significant.
So, the high precaution against abandoning a current solution for a non-superior one, comes at a cost. It comes with a high risk, due to low sensitivity, that we will miss at least some true improvements of small magnitude. To be precise, of a magnitude smaller than the minimum effect of interest we calculated our sample size for (regardless if it is classic fixed-sample size test or a sequential one, like an AGILE method test). This is why
Superiority tests should not be the default procedure, automatically applied to all A/B tests you do, but an informed decision you make for each case.
Non-inferiority tests are what we can do when the reasons for doing a superiority tests are not present and the primary error we care about is different, that is: when we are more concerned about missing even the slightest improvement, or of rejecting an option that is just as good based on our primary KPI, but may have some benefits not measured in the test, like reduced cost, complexity, maintenance, etc. Before we go into some practical examples for the application of non-inferiority tests, let’s first make sure we know what they are exactly.
What is non-inferiority testing?
It is simply a statistical test in which the null hypothesis is that the tested variant is performing worse than the control by a significant margin:
Null hypothesis: variant(s) < control or more precisely variant(s) < control – δ, where δ is a difference at which we consider the control and variant equal for any practical reasons. That is, even if the new solution we implement after the A/B test is in fact doing worse than the existing one by a margin of δ, we would still be OK in implementing it.

With a non-inferiority test we declare that we will act under the assumption that:
The error we want to avoid the most is the error of failing to implement a new solution, which is about equal, or better than what we currently have
I believe there are many, many cases in online experiments, both in conversion rate optimization / UX testing and in online marketing experiments, where this is exactly the case. I have no doubt any marketer or CRO expert would be able to quick about at least half a dozen such experiments they did in the past months. I give my own examples in “When to perform a non-inferiority A/B test?” below.
Here is a comparison between the confidence intervals of three tests, all stopped for success:
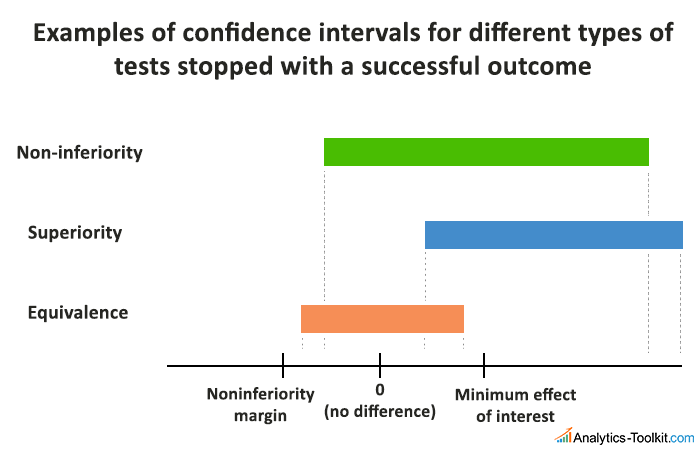
The above is a more visual illustration of the concept which should help in understanding it. A non-inferiority test can be thought of as a superiority test + equivalence test, as its alternative hypothesis covers the equivalence test alternative and the superiority test alternative. If you think in terms of null hypothesis, it is the null for a superiority test minus the null of an equivalence test.
The choice of a noninferiority margin, also called an equivalence margin, is key. It must be done based on objective evaluation of the magnitude that can to be considered non-significant. Sample size considerations enter into the decision-making process, same as in a superiority test (except in the “easy decision” cases where it is a bit different, explained below). No one has unlimited time on their hands. A simple rule might be that the noninferiority margin is set to the same size of the minimum effect of interest that you’d set in a superiority test.
Regardless of the method you use, it is of utmost important to get buy-in on this decision from all key stakeholders before the is started. Doing so after you have data will almost inevitably lead to bias in one direction, or the other.
Statistically the tests (z-test, t-test, chi-square, sequential variants of these and others) work exactly the same – the math is the same. The difference is in the parameters we specify as they need to describe another null hypothesis. It is also possible to analyze a test planned as a superiority test, as a non-inferiority one. Sequential A/B tests such as tests using the AGILE A/B testing approach, however, should be designed as non-inferiority tests from the very beginning, since the design affects the stopping probabilities.
See this in action
Advanced significance & confidence interval calculator.
If you are using custom code (Excel, R, Python, etc.) to do your calculations, you will still be able to usе it, with some modifications for sample size calculations and p-values, while one-sided confidence intervals can be used without any additional changes. See references [2], [3] & [4] below if you are interested in the technical details on the most common approaches.
If you are using a third-party platform, it must specifically support the design and evaluation of non-inferiority tests, or you must have the freedom to specify your null hypothesis. I believe many tools just assume a superiority trial by default and allow no option to specify it, but hopefully this will change. Alternatively, you can use a third-party tool for the statistical analysis only. Clients of our toolkit would be happy to know that both our Sample size & Statistical significance calculator and our A/B Testing Calculator explicitly support non-inferiority tests in their fullest.
When to perform a non-inferiority A/B test?
In my white paper on non-inferiority testing I differentiate between two types of cases that are suitable for applying a non-inferiority test. I call them “side benefits” cases and “easy decision” cases. Let’s examine each of them.
Non-inferiority testing for “side benefits” cases
This is the most unambiguous case, in which the new solution you want to test has benefits not measurable in the test. Naturally, a solution having such benefits which performs equivalently to the existing solution, or even slightly worse, would still be the preferred solution, for example due to lower maintenance costs, or better brand integrity, etc.
Some concrete A/B testing examples: removing 360-degree shots of products can result in significant savings for an online merchant, and they might even tolerate a bit lower conversion rate; removing a free trial period that requires one or two additional customer support personnel can be great if the conversion rate to a paid account remains about the same; removing several payment methods may significantly simplify payment processing and invoicing, so if it only affects conversions a little bit, it might well be worth doing it.
Non-inferiority testing for “easy decision” cases
This is where it gets interesting, since in many online marketing/UX tests the solution to be tested is:
- easy and cheap to implement
- costs nothing to maintain
- reversible, in many cases with ease
- faces little to no internal and external opposition
Contrast these to the reasons one will want to do superiority testing – it’s a complete reversal. On top of that, in many such cases re-testing is also cheap and easy, including testing the cumulative changes of, say, 10 consecutive A/B tests versus the control from test #1.
Examples include trivial changes such as color or text changes on a Call to Action (CTA) element, many copy or image changes, the removal or addition of some elements of the site or third-party functionality such as trust signals, live chat, etc. Think of all the tests you’ve done and case studies you’ve read where the test was for a simple button change or layout change, or text change. I’m willing to bet a decent sum of money (and I’m no gambler!) that the number of such tests would be higher than 50% of all, meaning that non-inferiority testing should have wider adoption than superiority tests!
Benefits of using non-inferiority designs
The benefit in the “side benefits” case is quite clear: it is that you would have statistical evaluation of a new solution, that you want to adopt, making sure it is not significantly worse than the existing one. There is simply no way you can do that with a superiority test – the new solution must be better than the old one in order to pass the test reliably. If you set your noinferiority margin at the same level as you would set your minimum effect of interest, then you gain nothing in terms of sample size / speed of testing. The math is such that the required time to run the test would be the same for all practical considerations.
The more interesting case is the “easy decisions” case, since it is here that you can get a very significant improvement in the time required to run a test, allowing you to run many such tests in the same time it would take you to run one “classic” superiority or non-inferiority test.
Let’s say there is an online SaaS website for which we want to test a simple change of a button text. Currently, the button says “Free Trial” and we want to test whether adding an action-inducing word to it will change things, so the variant we A/B test is simply “Start Free Trial”. The current free trial conversion rate is 9% and if you were running a classic superiority test you would set we would be able to reliably detect an improvement of 5% or more. However, since this is easy to implement, costs nothing to maintain and is easily reversible, we can design it as a non-inferiority test where we would be happy to get data that allows us to make a decision faster, even if it means it might be equivalent to or up to 2% worse than the current text (the noninferiority margin is 2%). Here is what fixed-sample size test would require in terms of sample size per test arm with several different combinations of statistical significance and power levels:
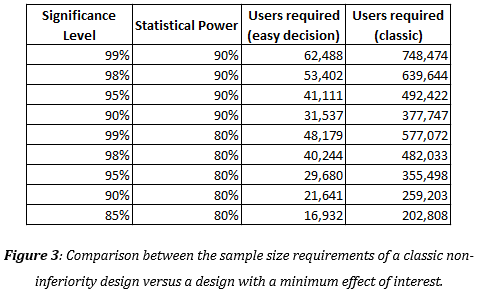
It easy to see that the easy decision design requires only 8.35% of what a classic non-inferiority design would require, giving us a whopping 12-fold increase in the speed to run the test. Of course, this number depends heavily on both the noninferiority margin and the minimum effect of interest chosen. Changing the minimum effect of interest from 5% to 2% means an easy decision design will now require 22.23% of a classical non-inferiority design, and about the same proportion of a superiority design with the same minimum effect of interest. Still a very, very nice improvement, but no doubt less spectacular.
Here is a graphical illustration of the difference between a superiority and an easy-decision non-inferiority design, which helps explain where the efficiency gain comes from:
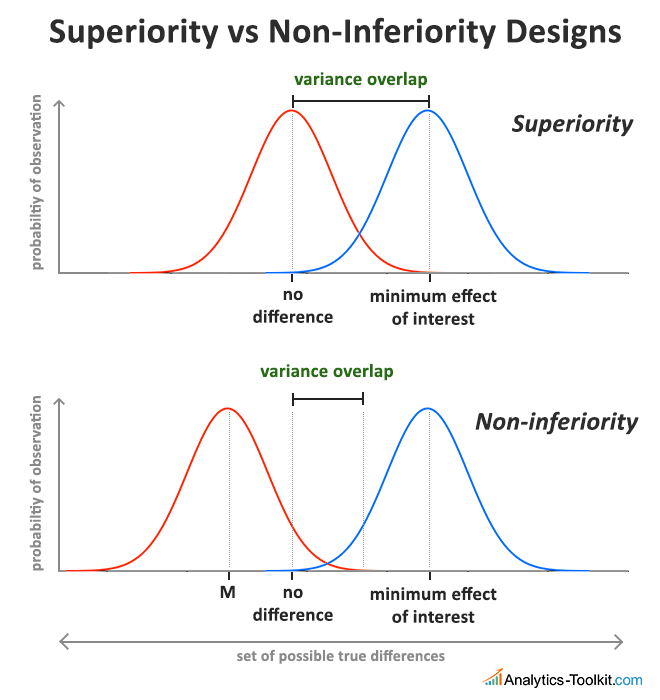
Needless to say, the two tests won’t have the same conclusions. With a superiority test, you have a certain guarantee that the tested variant is better than the control, while a non-inferiority test offers guarantees only about the variant not being significantly worse than the control. However, with the significant increase in speed, one is able to test much more variants in the same amount of time.
Combine this with multivariate testing where it makes sense, and a sequential testing approach (like AGILE), and you have a testing apparatus which can churn through a big number of easy to deploy testing variants in a relatively short amount of time. Each of them will likely only have the potential to cause a small improvement, but in doing many such tests, the improvements will add up much more quickly.
Maintaining momentum in any online business isn’t about doing only things that improve your bottom-line, it’s also about making enough such decisions.
Of course, this doesn’t mean to test poorly thought out variants – it will just hurt your bottom-line, but it does mean you will be able to test much more efficiently compared to both classic non-inferiority tests and superiority tests. Again, our statistical tools already support such tests: simply choose “non-inferiority” test, enter the noninferiority margin, then specify a minimum effect of interest.
See this in action
The all-in-one A/B testing statistics solution
The risk of cascading loses
While non-inferiority tests have significant benefits in particular situations, they, too, don’t come without issues. The cascading loses / accumulating loses concern is not particular to non-inferiority testing, but it is of higher concern due to noninferiority margin allowed. In a worst-case scenario, one can do everything properly and still end up accumulating loses over the course of several tests.
Let’s say we run 5 consecutive tests, each with a non-inferiority margin of 2%. If each A/B test ends up with a winning variant that is 2% worse than the control, we end up with a -10% lift:
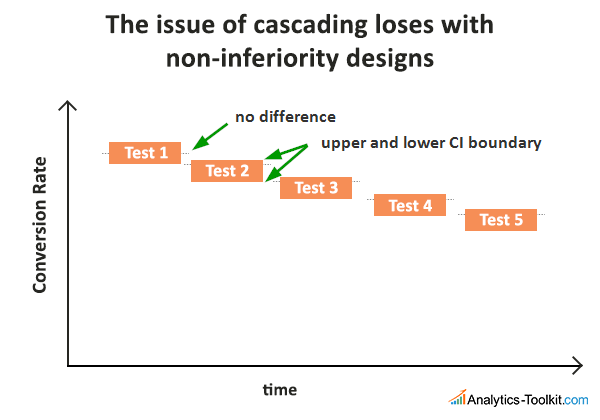
The risk is real and grows bigger with the number of A/B tests performed, especially if the observed confidence interval includes negative difference values. It is a risk one may or may not find acceptable in their particular circumstances.
It can be alleviated by using best practices, user research and common sense to guide the choice of solutions tested, as opposed to automated testing and/or testing for the sake of testing. A way to control/detect it, and to quantify one’s cumulative results, is to periodically run superiority or non-inferiority A/B tests where the control is a version of the element/page/process from a few tests ago, and the tested variant is the winner of the latest test. Such tests can combine the outcomes of many A/B tests affecting different parts of a website or ad campaign, in both variant and control, though the risks of running into the Simpson’s paradox and other segmenting issues increases.
Conclusion
The above is a fairly comprehensive and hopefully more accessible take on the topic of non-inferiority testing. If you are interested in a bit more in-depth take on it, consider downloading my free white paper: “Non-Inferiority Designs in A/B Testing“.
While superiority testing is currently the default position in both theory and practice, including A/B testing tools, I believe above I make a good case on why it should not be so. There are certainly cases where classic non-inferiority tests are the only viable solution, while in other cases “easy decision” non-inferiority designs provide both a better fit with regards to the error of primary concern, and a very significant increase in the efficiency of A/B testing by reducing the number of required users.
Non-inferiority testing doesn’t come without challenges: choosing a proper noninferiority margin adds additional difficulty in the planning phase of the test, while the worst-case scenario of cascading loses is something one should keep in mind. Still, these are far from insurmountable challenges and I think it’s about time the industry starts considering using non-inferiority tests, taking note from medical trials and other areas of scientific research where it is already standard practice.
Thoughts and suggestions on non-inferiority tests and how to increase their adoption within the CRO/UX and marketing industry are welcome in the comments below and our social profiles. Please, share the article to help the discussion.
References
1 Fisher, R.A. (1935) – “The Design of Experiments”, Edinburgh: Oliver & Boyd
2 Schuirmann, D.J. (1987) – “A comparison of the two one-sided tests procedure and the power approach for assessing equivalence of average bioavailability”, Journal of Pharmacokinetics and Biopharmaceutics, 15:657–680
3 Silva, G. T. da, Logan, B. R., & Klein, J. P. (2008) – “Methods for Equivalence and Noninferiority Testing”, Biology of Blood and Marrow Transplantation: Journal of the American Society for Blood and Marrow Transplantation, 15 (1 Suppl), 120–127
4 Walker, E., & Nowacki, A. S. (2011) – “Understanding Equivalence and Noninferiority Testing”, Journal of General Internal Medicine, 26(2), 192–196
About the author

Managing owner of Web Focus and creator of Analytics-toolkit.com, Georgi has over twenty years of experience in online marketing, web analytics, statistics, and design of business experiments for hundreds of websites.
He is the author of the book "Statistical Methods in Online A/B Testing", of white papers on statistical analysis of A/B tests, and has been a speaker at conferences, seminars, and courses. Georgi has been distinguished as a winner in the Data & Analytics category of the 2024 Experimentation Thought Leadership Awards.

